Note
The proposal in this document has been accepted by the Rubin Observatory Change Control Board and the Project Manager as LCR-2233. The design outlined here will be implemented for LSSTCam, and, if time and resources allow, retrofitted to ComCam.
1 Current Status¶
Now that crosstalk removal has been descoped from the Camera DAQ, there is only one version of the pixel image that can be and needs to be retrieved, rather than two. There are multiple destinations for this image:
Camera Diagnostic Cluster for automated visualization and rapid analysis
Active Optics System (AOS) for wavefront sensors only
Observatory Operations Data Service (OODS) for automated and ad hoc (including human-driven) rapid analysis
Data Backbone (DBB) for long-term reliable archival
For most science and possibly calibration images, Prompt Processing for execution of automated processing pipelines (primarily the Alert Production).
The first four of these are located in Chile at either the Summit or Base. The Prompt Processing systems are located at the LSST Data Facility (LDF), requiring transfer of the pixels over the international network. The desired latency for all of these is generally “as rapid as possible”, with the exception of the DBB, which has up to 24 hours. The DBB also transfers data over the international network, but more slowly.
The first four of these are expecting to persist the pixel data as FITS files in RAM disk or persistent file storage (e.g. GPFS); as a result, it makes sense to do the same for Prompt Processing as well, though care should be taken to minimize latencies in order to avoid delaying alert generation.
All of these need to ingest the image files into a Data Butler repository to enable pipeline code to access the images using butler.get().
It is currently expected that these would be separate Butler repos.
The data ID used for the Butler should include either the image name or group ID and image (“snap”) number as well as the raft and detector/CCD identifiers.
Each system needs to send an event to indicate that the image has been ingested and is thus available to pipelines.
The current baseline, as implemented for LATISS, has an image writer component of the Camera Control System (CCS) writing to the Camera Diagnostic Cluster. Another instance of this image writer is intended to be configured and deployed for the AOS. The OODS and DBB are fed by the DM Archiver and Forwarders, which are a separate image retrieval and writing system. Prompt Processing has not yet been implemented, but it is supposed to use another instance of the Forwarders. In addition, a Catch-Up Archiver is meant to feed the DBB with images that were otherwise missed, including those taken during a Summit-to-Base network outage.
An independent Header Service retrieves image metadata from events and telemetry, writing a single metadata object for each image that can be used by any image writer.
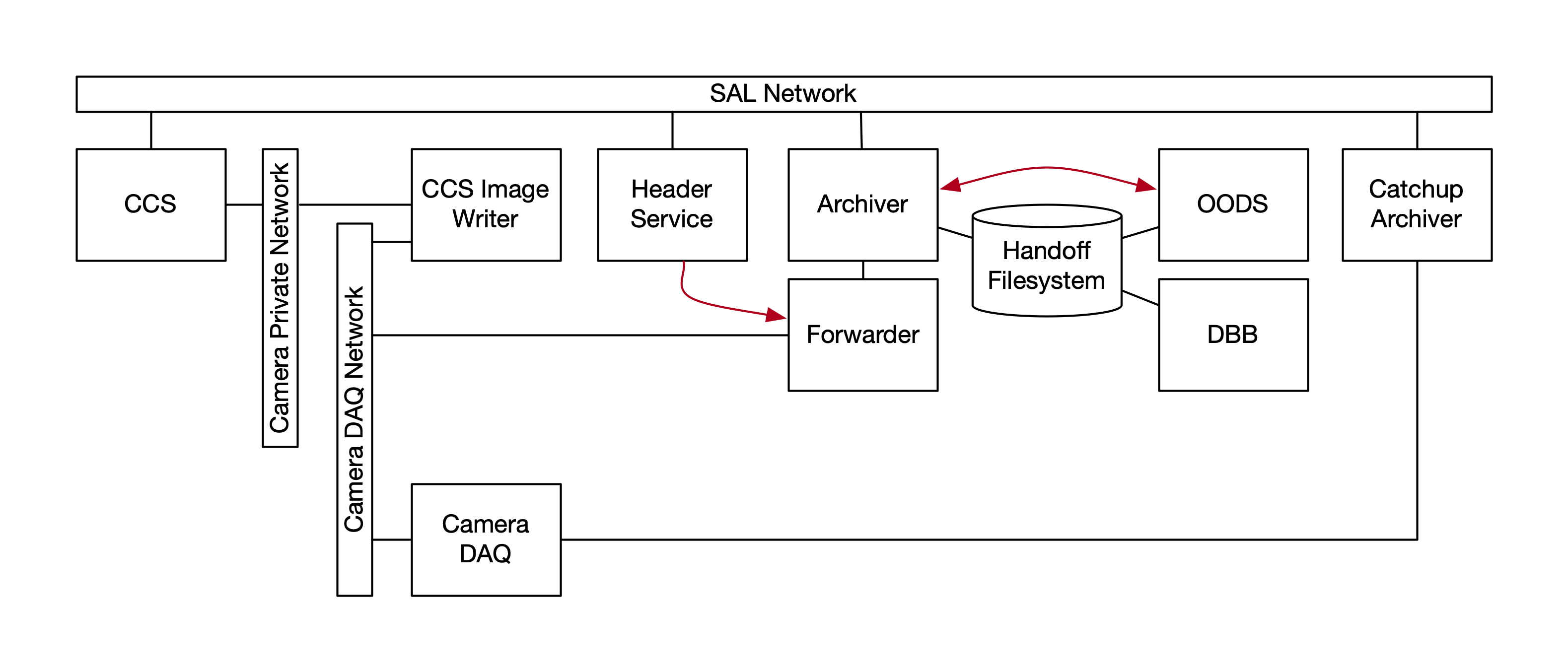
Figure 1 The image writing system as currently baselined (somewhat simplified). The red arrows represent image-completion messaging from the Archiver to the OODS and “header” metadata transfer from the Header Service to the Forwarder (via the Large File Annex).¶
2 Design Proposal¶
We propose to combine and simplify some of these components.
2.1 CCS-Based Image and Metadata Writing¶
Image writing will be performed exclusively by the CCS image writer code. There will be one instance for CCS and DM uses. We will attempt to use the same instance for AOS uses, but it may be necessary to have a separate instance for this case. Note that guiders in guiding mode are a separate case and not in the scope of this document.
The CCS software will listen for Header Service large file object available events and merge that metadata with the pixels in the files that it writes.
This reduces the number of code bases that need to be supported, saving development effort. It would remove two clients from the DAQ (Forwarder and Prompt Processing Forwarder). It would remove the need for any DAQ clients to live at the Base, thereby removing the need for DAQ networking to extend over the DWDM.[1] Since the CCS is absolutely necessary for image-taking, it would remove the possibility of images being taken with the Archiver or Prompt Processing disabled. (Such images would eventually be retrieved by the Catch-Up Archiver, but they would be at least delayed for Prompt Processing purposes.) It eliminates the current duplication of images and resultant confusion. It ensures that engineering images taken under CCS control are captured the same way as images taken under OCS control (though possibly with less metadata).
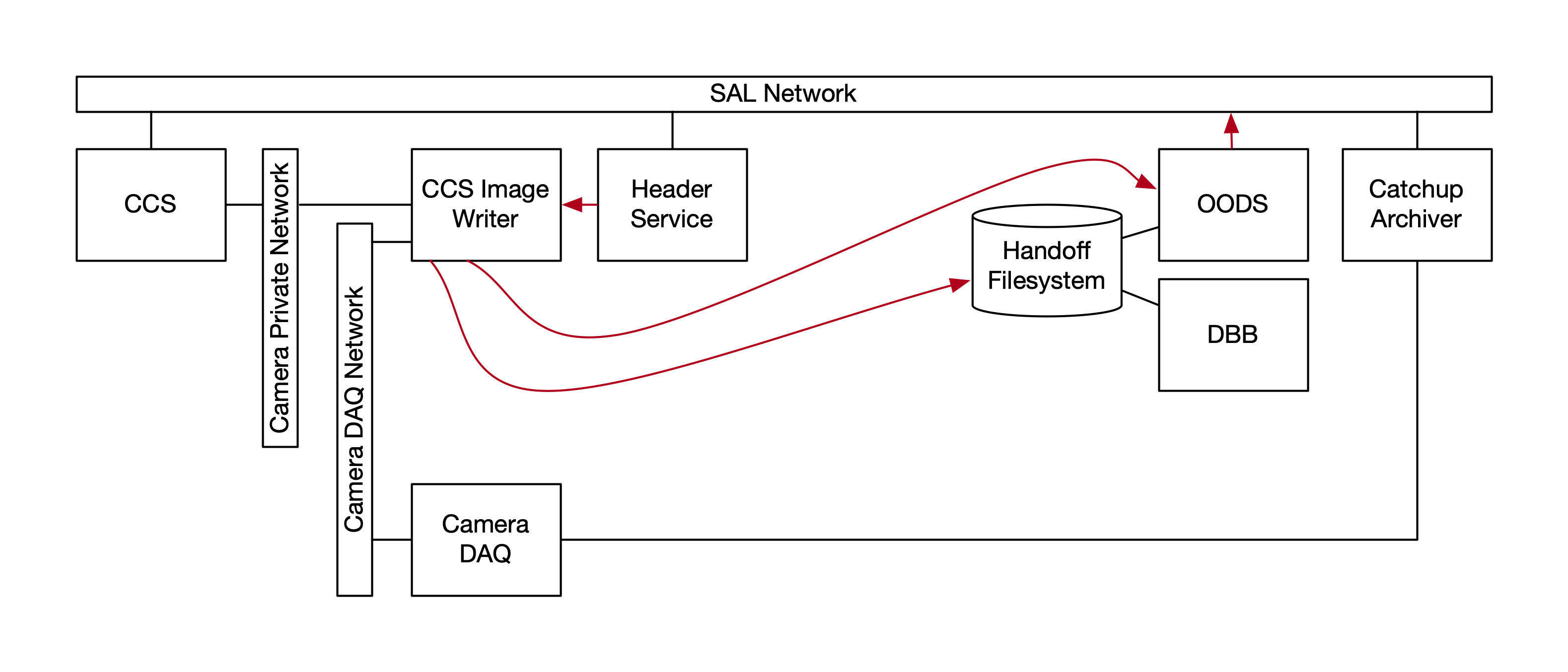
Figure 2 The image writing system as proposed. The Archiver and Forwarder are removed. The Header Service metadata goes to the CCS Image Writer. Image-completion messages go from the CCS Image Writer to the OODS. Images are copied to the Handoff Filesystem.¶
2.2 Post-Writing Commands¶
To enable transfer of the pixel images to the systems that need them, the CCS image writing software will be enhanced to accept commands or scripts that can be executed once an image and its metadata has been written successfully. These commands will be configured into the CCS software by specifying a destination name, the command, an opaque parameter string, and a priority order. This configuration information will be published in SAL messages as part of the CCS configuration.
After an image is written, all commands will be executed on that image, in priority order. Commands should be executed in parallel, but it should be possible to limit the number of commands being executed at the same time at the cost of increased latency. Such throttling may be useful to limit network bandwidth usage.
Any system software packages and authentication information required by the available commands, as well as the software for the commands themselves, will be specified as part of the deployment environment.
Each command will be given a first argument consisting of the filename for the image, which will include the image name, including the observation day (date in the UTC-12 timezone) and the image sequence number, as well as the raft and sensor of the image. Each command will also be given a second argument consisting of the opaque string configured for that command.
On completion, each command must provide exit status. The CCS software will capture this exit status, and, if non-zero, the contents of the standard error stream from the command. It will then arrange to generate a SAL event indicating that the command completed, containing:
The destination name
The image obsid
The sensor corresponding to the file (e.g. R22S01)
The exit status
The standard error output if the exit status is non-zero
Occasional failures of this command mechanism are to be expected and are not fatal. In particular, failure of a command will not be a reason to place the CCS subsystem into fault state. All images that are not processed by this mechanism will be retrieved by the Catch-Up Archiver instead.
If a command runs for too long, specified by a configurable timeout, it should be killed and treated as having failed. Commands will not be retried on failure.
When the CCS is being shut down, all commands in flight may be killed. When the CCS restarts, any files discovered that did not have all commands executed may be ignored.
This facility can easily be used to copy files over networks to the Prompt Processing Distributors at the LDF and the OODS (whether at the Summit or Base). If messages are needed to trigger the OODS or other components, the sending commands can be appended to the copy commands in a script.
This facility can also be used to transmit image files directly over the Long Haul Network to a permanent filesystem or object store at the US Data Facility (USDF). This transmission is expected to be more reliable than using separate Distributor nodes, and it should be sufficiently low-latency since the Prompt Processing workers have to retrieve the pixel data over the network in either case. It also obviates the need for separate Prompt Processing and Archiving image transfers. It still may be necessary to have a separate process running to maintain persistent connections with the USDF; the command mechanism would trigger that process rather than performing the transfer itself.
2.3 Catch-Up Archiver¶
An independent Catch-Up Archiver will be needed in any case. Neither the DM Archiver/Forwarder nor the CCS image writer can be considered 100% reliable in terms of capturing all science images. The Catch-Up Archiver will reuse code from the CCS image handler for catalog enumeration, pixel manipulation, and file output, but it is a separate CSC that interfaces to the DBB to know which images have already been archived and to ingest images that it writes.
The Catch-Up Archiver can live at the Summit. If 3 machines with 1 GB/sec (over 10Gb Ethernet) inbound and outbound network bandwidth are allocated to the Catch-Up Archiver, it should be possible to copy data to the Base at the rate of one 12 GB (uncompressed, even) image per 4 seconds, 4X the normal image capture rate, which is at most one image per 17 seconds. This is sufficient to empty the buffer after even a long outage.
3 Transition Plan and Personnel¶
The first steps in a transition to this design would be:
Have the image writer get metadata from the Header Service. This is already planned, but it would be critical to get this in place ASAP.
Implement the post-capture command facility. At this point, minimal functionality would be available for LATISS and test stands, including ComCam.
While Tony Johnson (the CCS manager) is quite busy with LATISS commissioning, ComCam testing, and LSSTCam integration and testing, at least Steve Pietrowicz from NCSA could help with the Java-based aspects of this transition.
3.1 Further Additions¶
The following additions would need to be made after the initial transition:
Sufficient Summit-located compute resources, including hot spare nodes and network bandwidth, would need to be devoted to the Camera Diagnostic Cluster in order for it to also serve as the source of OODS, DBB, and Prompt Processing data.
The CCS image writer code would need to be enhanced to add robustness and fault tolerance. As currently written, it will fail to capture data if a node fails during or between image captures, and it must be manually reconfigured to recover to normal operation or else it continues to fail to capture data. The mechanisms used by the current DM Archiver should serve as a reference, but they would have to be ported to the Java environment of the CCS.
The CCS image writer code needs to be able to interface with the Catch-Up Archiver. The ability to retrieve images by name from a catalog listing is planned, but it may need to be implemented sooner and as part of a new CSC.
4 Header Service¶
Another possible simplification is to integrate the Header Service with the CCS image writer code. This has potential difficulties:
If there is a separate instance of the CCS image writer for the AOS, it may be difficult to keep these instances in sync or to keep multiple metadata objects separate.
Porting the current SAL-heavy Python code to Java may not be easy.
Nevertheless, this should be considered down the road, again because having the CCS perform this function can help ensure that it happens for every image and moves the metadata capture point close to the authoritative source for most of it.
5 2022 Implementation¶
In September of 2022, this mechanism was implemented as follows:
The CCS extracts image pixels from the Camera DAQ system, attaches FITS headers provided by the Header Service, and writes these locally as a FITS file. It writes header information for the image into a JSON “sidecar” file compatible with RawIngestTask.extractMetadata(), and it executes a command to compress the FITS image using tile-based Rice compression. Although these steps are not strictly required, they do speed up the process considerably.
The CCS executes separate commands to copy the JSON sidecar file and the compressed FITS image file to the embargo object store at the USDF.
These commands use HTTPS PUT to perform the transfer.
The path of the resulting objects is specified as {instrument}/{day_obs}/{obs_id}/{obs_id}_{raft}_{sensor}.fits.
The CCS image writers are configured with the necessary credentials to be able to write to the embargo object store.
The embargo object store is configured to emit notification messages via a webhook when new objects are created. The webhook performs an HTTP POST on a given URL.
A queueing service is deployed in USDF Kubernetes that receives the POST requests in a Flask application running within the gunicorn WSGI server.
The queueing service considers only notifications ending in .fits.
It determines the object store bucket in which the object was created and posts the object pathname to a Redis queue named after that bucket.
The ability to handle multiple buckets allows the Summit and Test Stands to be handled by the same system.
Ingest services deployed in USDF Kubernetes, one per bucket, watch the Redis bucket queues.
These ingest services run in containers based on a particular release of (much of) the LSST Science Pipelines, including the obs_lsst package.
When new paths are placed in the bucket queues, the workers remove one at a time and add them to a worker-specific queue, also in Redis.
All paths on the worker queue are read and passed, one at a time, to the run method of a pre-instantiated RawIngestTask.
The success and failure callbacks of that task are used to determine whether to remove a path from the worker queue, with removal occurring on success or metadata translation failure, while ingest failures are left in the queue for retrying.
All successful ingests are then passed to the run method of a pre-instantiated DefineVisitsTask.
The bucket queue implementation allows for multiple queueing servers (and multiple request handlers within any single server) to be active at the same time, as adding to the bucket queue is an atomic operation. The worker queue implementation similarly allows for multiple ingest workers per bucket, which will be necessary to scale to large numbers of images. Both of these features enable these services to work smoothly as Kubernetes Deployments. Note that while the queueing service only needs one active request handler at a time, during restarts and upgrades, multiple may be running at once.
A cleanup service deployed in USDF Kubernetes looks for worker queues that contain paths but which have been idle for a configurable time period. If any are found, it presumes that those workers are dead and transfers the paths from those worker queues back to the appropriate bucket queue. It presumes that Kubernetes will handle any required worker restarts.
The queueing and ingest services also write a number of other items to Redis to allow tracking of the number of image files handled per night, success and failure rates, latencies, and failure messages. These are expected to be used in a future monitoring system.